
You Should Distill, Too
When using ChatGPT, Cursor, or other AI products, adopting the philosophy of distillation could help you achieve better results.

Intro
With recent flooding discussions around DeepSeek, one concept appears in almost every article, news piece, and podcast: Distillation.
In the LLM training space, distillation is a technique to transfer knowledge from a large "teacher" model into a smaller "student" model, allowing the smaller model to perform better while reducing inference costs.
For us users, we can and should use the same strategy in our daily interactions with AI products.
Why
Currently, the models we have at hand can be roughly categorized into two types:
Reasoning models: OpenAI o1/DeepSeek R1
General-purpose models: OpenAI GPT-4o/Claude 3.5 Sonnet/DeepSeek V3
While reasoning models outperform general-purpose models in benchmarks, why can't we just use o1 or R1 all the time? There are several reasons:
Cost: Whether accessed via ChatGPT or APIs, reasoning models come at a significantly higher price. For example, Plus plan users get only 50 o1 messages per week on ChatGPT. DeepSeek R1, an o1-equivalent reasoning model, offers ~93% lower inference costs, which definitely could be a game changer - but other factors still matter.
Speed: Reasoning models build on their unique and powerful "reason before answer" approach, or Chain-of-Thought, but this introduces significant latency that may be intolerable for certain tasks.
Overthinking: Sometimes, reasoning models overthink and generate less-than-ideal responses. In such cases, the extra time spent on reasoning feels even more like a waste.
Offline-only: There are cases where you do need up-to-date knowledge.
How
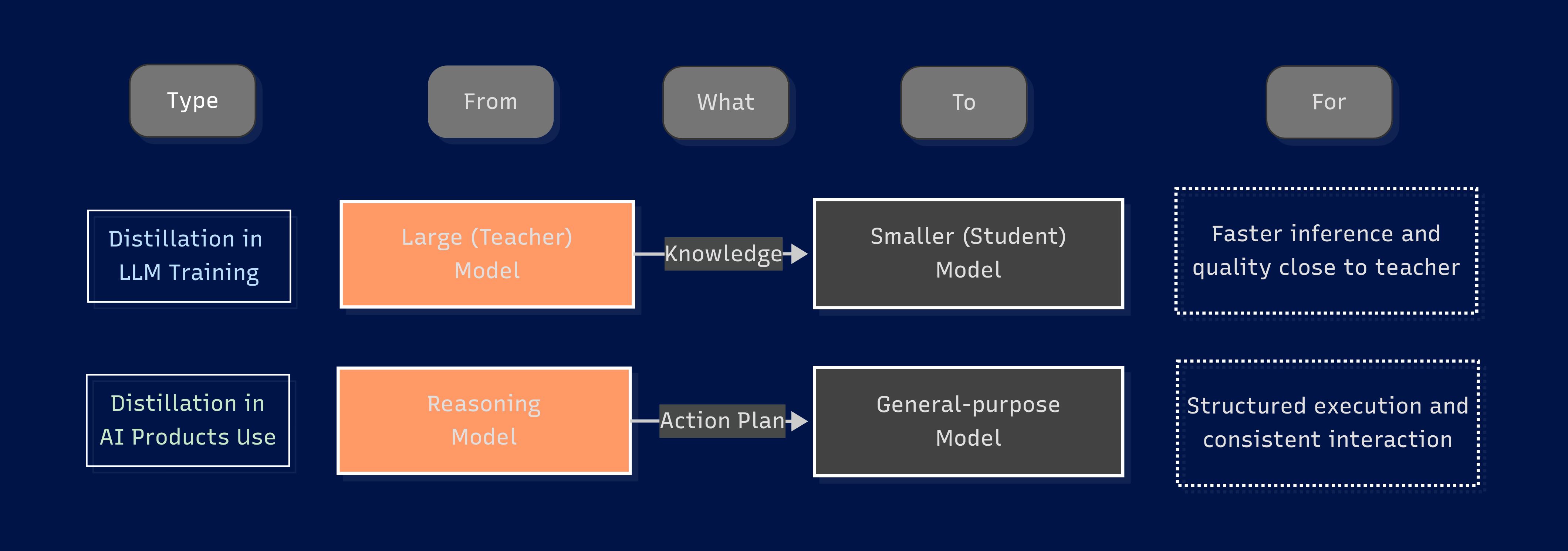
It's simple, just like distillation in model training - for certain (not all) tasks, start by asking a reasoning model to generate a detailed "action plan" for the general-purpose model to follow. This plan should always include:
Your goals
High-level strategy
Critical context
Conversation guidelines (since you’ll likely have multiple rounds of interaction with the general-purpose model)
Feedback rules (when the model should ask for human input)
This method is highly effective in many scenarios and has already become my best practice. Here are two use cases, and I know others are using this technique (or similar ones). If you have additional use cases, feel free to share them in the comments.
Case 1 - Coding a New Project
I recently wrote a Chrome extension using Cursor. Initially, I started directly with Cursor, and it quickly became chaotic. I encountered problems like message transmission between modules and Chrome’s module-specific operation restrictions. These issues were beyond Cursor’s capability to properly fix. After getting a detailed design from o1, I passed it to Cursor to start fresh, and everything went much more smoothly.
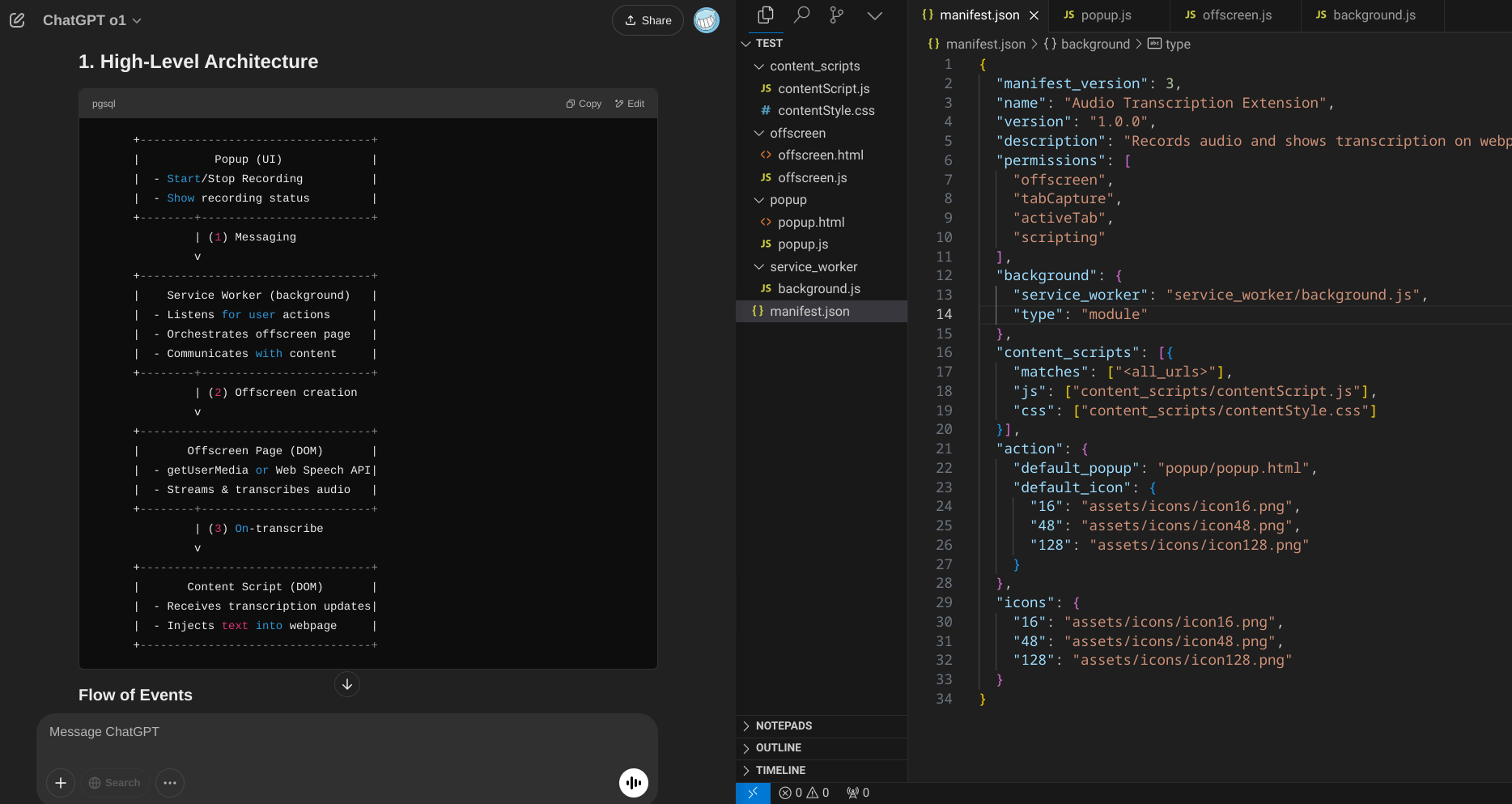
Learning from that experience, I now begin every new project by asking o1/R1 to generate a system design. This includes the code architecture, key contexts (e.g., API documents, known restrictions), and personal preferences (e.g., code style, log rules) based on my goals. Compared to giving instructions directly to Cursor, I find this approach produces much better-structured code with a clearer architecture. It also saves significant time by preventing messy dependencies and ensuring the right approach for implementing features.
Case 2 - Reading a Paper
With new papers in AI falling like snowflakes, reading has become a daily task. Each reading session is unique - a mix of personal background, the paper’s topic, and the specific angle you’re interested in.
For me, staying in flow state while reading is crucial. To achieve this, I first send my background, a summary of the paper, my key focus areas, and my preferred conversation style to a reasoning model to generate a task brief. I then pass this brief to a general-purpose model. During the actual reading, I simply send copied text from the paper or ask questions as needed, allowing for quick and seamless interactions.
Speed matters here. I initially tried using a reasoning model directly, but its long thinking process constantly disrupted my flow. For DeepSeek’s most recent paper, I used the R1/V3 combination with this approach, and it worked exceptionally well.
Next
Here's what I expect or hope will happen:
AI applications adopting this approach: I’d love to see Cursor using reasoning models to plan before execution for complex tasks. Currently, Cursor (using Composer mode, which combines Cursor’s own model with Claude 3.5 Sonnet) is often overconfident and breaks things. This approach would also make it more agentic - like humans, reasoning before acting.
Model improvements: If reasoning models become faster, cheaper, and smarter, we might not need this approach at all. OpenAI’s newest o3-mini family, launched last Friday, is definitely a step in that direction - offering lower costs, improved speed, and multiple reasoning levels to choose from (mitigating overthinking).